
Summary:
- Fingerprinting methods detect plagiarism efficiently by hashing k-grams, using Rabin–Karp and winnowing algorithms.
- Strengths include high scalability, speed, precision in direct matches, and language independence.
- Limitations arise with paraphrasing or synonym substitution, highlighting the need for hybrid semantic approaches.
- Integrating MinHash and semantic techniques enhances detection accuracy, balancing efficiency and effectiveness.
Plagiarism detection is a crucial task in academia and content creation, aiming to identify when text has been inappropriately copied or reused without attribution. Modern plagiarism detection methods range from straightforward string matching to sophisticated semantic analysis. One widely adopted approach is document fingerprinting, a hash-based text similarity technique that generates a compact representation of a document’s content. Fingerprinting works by breaking the text into smaller units and hashing these segments to create unique identifiers (the “fingerprints”). These fingerprints enable efficient comparison of documents by focusing on matching hashed segments rather than raw text strings. This method has become a cornerstone of large-scale plagiarism detection systems because it significantly speeds up search and comparison across vast document repositories (Schleimer et al., 2003). In this article, we focus on how hash-based fingerprinting works for plagiarism detection, examine its technical underpinnings (including the Rabin–Karp algorithm and the winnowing algorithm, as well as MinHash techniques), and discuss the strengths and weaknesses of this approach. We also consider how effective fingerprinting is in practice, and in which scenarios it excels or struggles, thereby providing insight into its role in current plagiarism detection efforts.
Fingerprinting as a text similarity approach
Fingerprinting methods treat a piece of text as a sequence of small chunks and reduce each chunk to a numerical hash. By comparing these hashes between documents, one can quickly find identical or highly similar substrings without needing a direct character-by-character scan. This approach is fundamentally a text-based similarity measure that looks for exact or near-exact overlaps in content (Hoad and Zobel, 2003). The underlying idea is that if two documents share sufficiently many identical hashed segments, it is very likely that one has copied from the other. Fingerprinting is extrinsic plagiarism detection (comparing a document against external sources) and assumes access to a corpus of sources against which the suspicious document is checked. It does not attempt to understand the meaning of text; instead, it relies on matching patterns of characters or words. Because of this focus on surface text, fingerprinting is extremely fast and language-agnostic – the same method can be applied to English, Arabic, Malayalam or any text, after minimal preprocessing (Nagoudi et al., 2018; Sindhu and Idicula, 2015). The method has been deployed in many plagiarism detection tools due to its efficiency and robustness in catching verbatim copying. In the following subsections, we explain the key components of fingerprinting: splitting text into k-grams, hashing these segments (often via rolling hash algorithms like Rabin–Karp), selecting representative hashes (using techniques such as winnowing), and measuring similarity (for example with Jaccard index or MinHash sketches).
K-grams and hashing of text segments
Fingerprinting begins by preprocessing the text and dividing it into contiguous substrings of length k, commonly called k-grams. These substrings can be sequences of characters or tokens (words), depending on the implementation. For instance, using character 5-grams, the sentence “plagiarism detection” would be split into segments like “plagi”, “lagia”, “agiar”, and so on. Using word-level k-grams, the text might be chunked into overlapping phrases of k words. The choice of k is significant: smaller k-grams (e.g. 3 characters) make it easier to find very short common phrases but risk more false matches, while larger k (e.g. 10 words) reduce false positives but might miss short overlaps. In practice, a moderate k (such as 5–8 characters or 3–5 words) is often used to balance sensitivity and specificity (Wibowo et al., 2013).
Once the text is split into k-grams, each k-gram is converted into a numerical hash value. A hash function maps the string of characters in the k-gram to an integer, typically in a large range (for example, a 32-bit or 64-bit integer space). This hash acts as a surrogate for the actual substring: two identical k-grams will produce the same hash. A common technique for efficient hashing of substrings is the Rabin–Karp rolling hash algorithm (Karp and Rabin, 1987). The Rabin–Karp approach treats a string as a number in a chosen base (for example, treating each character’s ASCII code as a digit in a base-B number) and computes hashes in an incremental way. It starts by hashing the first k characters, then for each subsequent k-gram (which slides one character forward) it updates the hash in constant time instead of recomputing from scratch. Specifically, a rolling hash will subtract the contribution of the outgoing character, multiply by a base, and add the incoming character. This allows the algorithm to scan through text in linear time, producing a hash for every k-length segment very efficiently (Karp and Rabin, 1987). The resulting set of hash values for all k-grams in a document can be seen as the document’s raw fingerprint. In many plagiarism detectors, additional normalisation is applied before hashing – for example, converting all text to lowercase and removing punctuation or stopwords – to ensure that trivial differences in formatting do not prevent matches. After hashing, a document might be represented by thousands of hash values (one per k-gram). Storing and comparing every one of these would still be cumbersome for very large document collections, so fingerprinting methods often include a step to select a representative subset of hashes that characterise the document.
Selecting representative fingerprints (winnowing algorithm)
Choosing a smaller subset of k-gram hashes as the document’s “fingerprints” is vital for scalability. An effective selection strategy needs to retain enough hashes to catch copied passages, while discarding others to minimise data size and avoid spurious matches. A naive selection (like picking every ith hash or randomly sampling hashes) could miss matches if the plagiarised text shifts position or if different documents have varying lengths. A more robust technique is the winnowing algorithm (Schleimer et al., 2003), which has become a standard for document fingerprinting. Winnowing works by sliding a fixed-size window over the sequence of hash values and, for each window, selecting the minimum hash value in that window as a fingerprint. For example, if we use a window of size w hashes, then among each group of w consecutive k-gram hashes, the smallest (or sometimes the rightmost smallest) hash is chosen. These minimal hashes serve as the fingerprints stored for the document. Winnowing guarantees that if two documents share an exact substring longer than the window size, they will share at least one common fingerprint (Schleimer et al., 2003). This property makes winnowing resilient to content shifts: even if a copied passage appears at a different location in another document, as long as the passage is sufficiently long, the same minimum hash will be picked in both. The window size w is typically set such that any substring of a certain threshold length (for example, 50 characters) will produce a fingerprint. By adjusting w relative to k, one can control the minimum plagiarism fragment size that is detectable. A larger window yields fewer fingerprints per document (improving efficiency) but requires longer verbatim segments to catch a match, whereas a smaller window increases sensitivity at the cost of more fingerprints. Winnowing thus strikes a balance between robustness and conciseness of the fingerprint set. The outcome of this process is a set (or multiset) of representative hash values that succinctly characterise the content of the document. For instance, one study applied winnowing with a rolling hash on student assignments and computed similarity based on the overlap of selected fingerprints, using a Jaccard coefficient to quantify the result (Shrestha et al., 2023). The use of winnowing in that system enabled fast detection of copied segments while ignoring minor edits and differences in alignment. In general, fingerprint selection ensures that plagiarism detection can scale to large datasets – by greatly reducing the amount of data each document is represented by – without losing the ability to detect significant overlaps (Schleimer et al., 2003; Wibowo et al., 2013).
Similarity metrics and MinHash for document comparison
After generating fingerprints for documents, plagiarism detection systems need to compare these fingerprints to identify potential matches between a suspicious document and source documents. The simplest approach is to compute the set intersection of fingerprints: if document A and document B share many hash values in common, it implies they have many identical k-gram substrings. A popular measure for quantifying this overlap is the Jaccard similarity coefficient. Given fingerprint set F(A) for document A and F(B) for document B, the Jaccard similarity is defined as:
J(A,B)=∣F(A)∩F(B)∣∣F(A)∪F(B)∣ .J(A,B) = \frac{|F(A) \cap F(B)|}{|F(A) \cup F(B)|} \,.J(A,B)=∣F(A)∪F(B)∣∣F(A)∩F(B)∣.

A high Jaccard value indicates a large portion of content overlap between the two documents.
Alternatives like the Sørensen–Dice coefficient (which is $2|F(A)\cap F(B)|/(|F(A)|+|F(B)|)$) are also used; both metrics serve to normalise the raw count of matching hashes by the size of the documents.
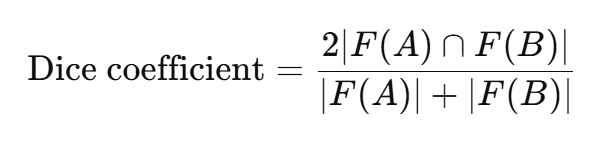
In plagiarism detection, a threshold on such a similarity score can trigger a flag – for example, if two documents have a Jaccard similarity above say 0.5 (50%), they might be considered likely plagiarised. This approach is effective for detecting direct copying and large-scale overlap. For instance, if a student copies whole paragraphs from a source, the fingerprints of those paragraphs will appear in both texts, yielding a high similarity score.
One challenge, however, is that comparing every pair of documents in a large corpus can be computationally expensive if done naively. To address efficiency in comparing fingerprints across millions of documents, many systems employ indexing and probabilistic techniques. A notable method is MinHash (Broder, 1997), which is a type of locality-sensitive hashing that provides a fast approximation of Jaccard similarity. Instead of storing all fingerprint hashes of a document, MinHash allows us to compute a fixed-size sketch (signature) for each document. This signature consists of a small number of hash values that probabilistically represent the set of all k-gram hashes. One way to construct a MinHash signature is to apply multiple independent hash functions to the k-gram set and record the minimum hash value produced by each function for that set. If two documents are very similar (i.e. share many k-grams), their MinHash signatures will also be similar (many of the same min values) with high probability. Using MinHash signatures, a system can compare documents much more quickly – by comparing, say, a vector of 100 integers for each document, rather than tens of thousands of raw hashes. MinHash was pioneered in the context of finding near-duplicate web pages (Broder, 1997) and has been applied to plagiarism detection as well to efficiently retrieve candidate matches from large repositories. Essentially, MinHash compresses the fingerprint set while preserving the resemblance information. This technique allows large-scale plagiarism search engines to query a new document’s signature against a database of signatures to find the most similar documents in sub-linear time. It is important to note that MinHash is an approximate method – it trades a bit of accuracy for speed – but in practice it can dramatically accelerate detection with minimal loss in recall for exact copies. In combination with robust fingerprinting algorithms like winnowing, this forms a powerful pipeline: fingerprints capture the overlaps, and MinHash-based indexing makes searching for overlaps feasible even on collections with millions of documents (Broder, 1997; Hoad and Zobel, 2003).
After potential source documents are identified (those with high fingerprint similarity or MinHash sketch similarity), a plagiarism detection system may perform a more detailed analysis or simply report the matching segments. In summary, fingerprinting techniques enable both pairwise similarity computation and efficient candidate retrieval. By converting documents to hash-based fingerprints, these methods drastically reduce the comparison complexity and make it practical to detect plagiarism across the internet or large academic databases in a reasonable time frame.
Strengths of hash-based fingerprinting
Hash-based fingerprinting has several notable strengths that explain its wide adoption in plagiarism detection systems. Efficiency and scalability are among the biggest advantages. Comparing numeric hashes is extremely fast and can be done in constant or sub-linear time using hash table lookups or sorted list intersections. This is far more efficient than naive text comparison which is linear in document lengths for each comparison. With fingerprinting, a new document can be checked against a corpus of thousands or even millions of sources in seconds, because the search boils down to finding matching hash values rather than scanning full texts. In fact, the fingerprint index can be structured to retrieve matching documents in near constant time (for example, using inverted indexes that map each hash to the list of documents containing it). This scalability is critical for real-world plagiarism detection services like academic integrity platforms, which must handle huge databases of journals, books, and student papers.
Another strength is the language independence and adaptability of fingerprinting. Because the method relies only on raw text patterns, it does not depend on language-specific resources like thesauri or semantic models. It can be applied to any language script (English, Arabic, Malayalam, etc.) as long as the text can be processed into a sequence of tokens or characters. Researchers have successfully utilised fingerprinting for a variety of languages, including those with complex morphology or writing systems, by adjusting preprocessing steps. For example, in detecting plagiarism in Arabic documents, one system used hashing of words along with language-specific normalisation (such as removing diacritic marks and using a stemming algorithm) to account for Arabic’s linguistic features, and achieved high precision and recall in identifying copied passages (Nagoudi et al., 2018). Likewise, fingerprinting has been applied to Malayalam (a Dravidian language) by using an appropriate tokeniser and has shown excellent performance in catching verbatim overlaps in Malayalam academic texts (Sindhu and Idicula, 2015). These examples demonstrate that fingerprinting methods are generally robust across different languages and can be adapted with minor tweaks (like choosing character vs word grams, or handling Unicode normalisation) to maintain effectiveness.
Fingerprinting is particularly powerful in detecting direct copies and straightforward plagiarism. If a passage is copied wholesale from a source, even if the plagiarist makes some superficial changes (such as changing punctuation or adding a few words), a substantial portion of k-grams will remain identical between the source and the suspicious text. The hash-based comparison will flag these common substrings reliably. Empirical evaluations confirm this strength: traditional fingerprinting algorithms can attain very high precision in catching copy-paste plagiarism. For instance, an experiment in an academic setting showed that using a winnowing fingerprint algorithm with Jaccard similarity was able to correctly identify plagiarism in student essays with high accuracy, missing very few cases of direct copying (Shrestha et al., 2023). Because fingerprints precisely capture shared sequences, they have a low false positive rate for unrelated documents – two completely different texts are extremely unlikely to share many identical k-gram hashes unless those are very short common words. This contributes to the precision of fingerprinting-based detectors, which often exceeds 90% for detecting literal plagiarism (Arabi and Akbari, 2022). The method essentially acts like a reliable sieve for filtering out non-matching documents and zeroing in quickly on those that share content.
Furthermore, fingerprinting methods are relatively simple to implement and integrate. The algorithms like Rabin–Karp rolling hash or MinHash are well-understood and not computationally heavy. They do not require training data or complex machine learning models; thus, they can be deployed in environments where resources are limited or where interpretability and determinism are important. This simplicity also means that fingerprinting can serve as a first-line detection mechanism: in many modern systems, an initial fingerprint match is used to narrow down candidate source documents, which can then be examined in more detail by humans or by more advanced algorithms. In summary, the strengths of fingerprinting lie in its speed, scalability, broad applicability, and high effectiveness at catching verbatim plagiarism. It remains a foundational technique in plagiarism detection and forms the core of many commercial and open-source plagiarism checking tools due to these advantages.
Limitations of fingerprinting and the need for semantic analysis
Despite its strengths, fingerprinting has notable limitations, especially when confronted with more sophisticated plagiarism techniques. The primary weakness is its reliance on exact or near-exact matches of text. If a plagiarist paraphrases the source material – changing words to synonyms, altering sentence structure, or expressing the same idea in a different way – the actual sequences of characters or words will change, and thus the k-gram hashes will no longer match. In such cases of obfuscated plagiarism, a pure fingerprinting approach can fail to detect the similarity, because there may be few or no identical substrings even though the underlying idea has been copied. For example, consider a source sentence: “Fingerprinting algorithms detect copied text by matching substrings.” A plagiarist might rewrite this as: “Algorithms that use document fingerprints identify duplicate content by finding common sequences.” Most of the words are different or reordered, so a k-gram fingerprint comparison might not register any match between the two sentences, even though they convey the same meaning. This vulnerability means that fingerprinting has lower recall for plagiarism that involves heavy paraphrasing, summarisation, or translation into another language. Indeed, studies have shown that traditional plagiarism detectors (which heavily use fingerprinting) often struggle with intelligently disguised plagiarism. One evaluation of multiple plagiarism detection systems found that while exact copy-paste was detected reliably, substantial paraphrases or synonym substitutions were missed by many tools (Foltýnek et al., 2020). In the context of our earlier example with the Malayalam language, a basic Rabin–Karp fingerprinting approach achieved only around 65% detection rate in a test dataset where some plagiarism involved rewording, whereas a more semantic-based similarity method achieved over 90% (showing fingerprinting’s drop in performance for non-verbatim copying). These findings underscore that fingerprinting captures lexical overlap but not semantic equivalence – it cannot “understand” text or catch plagiarism that is not reflected in literal shared sequences.
Another limitation is that fingerprinting methods have to make careful choices of parameters (k-gram length, window size, etc.), and these choices involve trade-offs. If the chosen k is too large, then even minor changes in the plagiarised text (like inserting an extra word in the middle of a copied sentence) will break the alignment of k-grams and potentially cause the method to miss a match entirely. On the other hand, if k is too small, many common phrases or random coincidences may match, raising false alarms. Similarly, the window size in winnowing determines the minimum detectable plagiarism span; content copied in fragments smaller than that window may evade detection. Plagiarists aware of these technical details could exploit them by fragmenting stolen text into pieces just below the detection threshold or by changing words at regular intervals to disrupt the k-grams. In practice, detection systems mitigate this by using multiple k-gram sizes or by post-processing matches (for instance, verifying that multiple fingerprints occur in proximity), but the fact remains that fingerprinting is inherently a surface-level approach. It is blind to deeper relationships between texts that do not manifest as literal overlaps.
To address these shortcomings, recent research and advanced plagiarism detection systems incorporate semantic analysis techniques alongside fingerprinting. For example, some systems implement a two-level approach: first apply fingerprinting to quickly find obvious overlaps and candidate documents, and then use a more semantic method (like comparing vector embeddings of sentences or using semantic word alignment) to detect paraphrased plagiarism (Nagoudi et al., 2018). Hybrid systems that combine structural fingerprint matching with semantic similarity checks have demonstrated significantly improved accuracy. Arabi and Akbari (2022) describe a hybrid plagiarism detection method that supplements traditional fingerprint matching with weighted semantic similarity measures; their approach was able to outperform purely fingerprint-based and purely semantic-based methods alone, achieving over 95% precision on a benchmark dataset. Similarly, Meuschke et al. (2018) developed HyPlag, a hybrid academic plagiarism detection system that uses conventional fingerprinting to identify exact matches and integrates additional analysis (including citation patterns and semantic context) to catch disguised plagiarism. These hybrid approaches illustrate that while fingerprinting provides speed and a first layer of detection, deeper analysis is often needed for full coverage of complex plagiarism cases. The combination of fingerprinting with natural language processing techniques (such as synonym dictionaries, embedding models like BERT, or semantic role labeling) enables detection of paraphrase or idea plagiarism that would otherwise slip through. It’s worth noting, however, that adding semantic analysis typically comes with increased computational cost and complexity. Thus, there is a trade-off: fingerprinting alone is simple and fast but limited in scope, whereas semantic methods are powerful but slower and resource-intensive. In practice, many systems use fingerprinting to drastically narrow down the search space, then apply semantic comparisons only to those few documents that share fingerprints or that are otherwise suspicious (Arabi and Akbari, 2022; Nagoudi et al., 2018). This way, they benefit from the strengths of both approaches.
In summary, the main weaknesses of fingerprinting are its inability to detect cleverly paraphrased or translated content and its sensitivity to parameter choices. These are mitigated by complementing fingerprinting with more advanced techniques in modern plagiarism detectors. Nonetheless, the fact that such complementary methods are needed does not diminish the essential role of fingerprinting – rather, it highlights that plagiarism detection is a multi-faceted problem, and hash-based fingerprints provide one vital piece of the solution by effectively handling the cases of direct overlap and serving as a foundation for further analysis.
Conclusion
Fingerprinting remains a fundamental technique in plagiarism detection, valued for its efficiency, simplicity, and effectiveness at catching unaltered or minimally altered text reuse. By breaking documents into k-grams and hashing them into concise digital fingerprints, this method allows rapid comparison across huge collections of text. It has proven its worth in both research and real-world applications – from academic journal plagiarism checks to large-scale web indexing – by enabling systems to pinpoint copied passages in seconds. The technical elegance of fingerprinting lies in how it reduces a complex text comparison problem to set intersection of hashes, leveraging computer-friendly operations while preserving meaningful signals of plagiarism. Moreover, fingerprinting’s language-agnostic nature has allowed it to be deployed in diverse linguistic contexts with success, detecting plagiarism in languages as varied as English, Arabic, and Malayalam with high precision (Sindhu and Idicula, 2015; Nagoudi et al., 2018). These methods are particularly adept at identifying verbatim copying, which continues to be a prevalent form of plagiarism.
However, as plagiarism tactics evolve, so too must detection strategies. The weaknesses of fingerprinting – especially its blindness to paraphrase and semantic equivalence – mean that on its own, it is not a panacea. In scenarios where plagiarists use more subtle techniques to mask copied content, purely hash-based methods will underperform. Therefore, the state of the art in plagiarism detection increasingly uses fingerprinting as part of a larger toolkit. Fingerprinting provides the cornerstone for scalable detection, flagging likely matches with low overhead, and then more advanced algorithms can inspect those matches in detail. This layered approach has been shown to yield excellent results, with hybrid systems reaching very high accuracy in detecting even heavily disguised plagiarism (Arabi and Akbari, 2022). In effect, fingerprinting handles the “low-hanging fruit” and casting of a wide net, while semantic analysis and other AI techniques handle the nuanced cases.
In conclusion, hash-based fingerprinting methods continue to be indispensable in plagiarism detection due to their speed and reliability for direct text similarity. Their technical specifics – from Rabin–Karp rolling hashes to winnowing and MinHash sketches – form a rich area of computer science that bridges information retrieval and digital forensics. Ongoing improvements, such as tuning fingerprint parameters or combining fingerprints with contextual analysis, ensure that fingerprinting stays relevant in the fight against plagiarism. As we look ahead, we can expect fingerprinting to remain deeply integrated in plagiarism detection systems, augmented by emerging techniques but still doing what it does best: efficiently spotting the tell-tale fingerprints of copied text in the vast expanse of written content.
References
Arabi, H. and Akbari, M. (2022). Improving plagiarism detection in a text document using hybrid weighted similarity. Expert Systems with Applications, 207, 118034. DOI: 10.1016/j.eswa.2022.118034
Broder, A. Z. (1997). On the resemblance and containment of documents. In Proceedings of the Compression and Complexity of Sequences (SEQUENCES ’97), pp. 21–29. IEEE Computer Society. DOI: 10.1109/SEQUEN.1997.666900
Hoad, T. C. and Zobel, J. (2003). Methods for identifying versioned and plagiarized documents. Journal of the American Society for Information Science and Technology, 54(3), 203–215. DOI: 10.1002/asi.10170
Karp, R. M. and Rabin, M. O. (1987). Efficient randomized pattern-matching algorithms. IBM Journal of Research and Development, 31(2), 249–260. DOI: 10.1147/rd.312.0249
Meuschke, N., Stange, V., Schubotz, M., and Gipp, B. (2018). HyPlag: A hybrid approach to academic plagiarism detection. In Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 1321–1324. DOI: 10.1145/3209978.3210080
Nagoudi, E. M. B., Khorsi, A., Cherroun, H., and Schwab, D. (2018). 2L-APD: A two-level plagiarism detection system for Arabic documents. Cybernetics and Information Technologies, 18(1), 124–138. DOI: 10.2478/cait-2018-0011
Schleimer, S., Wilkerson, D. S., and Aiken, A. (2003). Winnowing: Local algorithms for document fingerprinting. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, pp. 76–85. DOI: 10.1145/872757.872770
Sindhu, L. and Idicula, S. M. (2015). Fingerprinting based detection system for identifying plagiarism in Malayalam text documents. In Proceedings of the International Conference on Computing and Network Communications (CoCoNet 2015), Trivandrum, India. DOI: 10.1109/CoCoNet.2015.7411237
Wibowo, A. T., Sudarmadi, K. W., and Barmawi, A. M. (2013). Comparison between fingerprint and winnowing algorithm to detect plagiarism fraud on Bahasa Indonesia documents. In Proceedings of the 2013 International Conference on Information and Communication Technology (ICoICT), Bandung, Indonesia, pp. 219–223. DOI: 10.1109/ICoICT.2013.6574580