
Summary:
The most promising technical methods of plagiarism detection over the last 10 years combine deep learning, semantic analysis, and hybrid approaches to address increasingly sophisticated forms of plagiarism.
1. Introduction
Over the past decade, plagiarism detection has evolved rapidly, driven by advances in machine learning, deep learning, and natural language processing (NLP). Traditional string-matching and token-based methods, while effective for verbatim copying, have struggled with more complex forms such as paraphrasing, translation, and idea plagiarism.
Recent research highlights the emergence of semantic analysis, deep learning architectures (including transformers and LSTM networks), and hybrid systems that integrate multiple features (lexical, syntactic, semantic, and even non-textual) as the most promising technical methods for detecting both simple and highly obfuscated plagiarism (Foltýnek and Meuschke, 2019; Sajid et al., 2025; Amirzhanov, Turan and Makhmutova, 2025; El-Rashidy et al., 2023; Arabi and Akbari, 2022; Xiong et al., 2023; El-Rashidy et al., 2022; Roşu et al., 2020; Abisheka, Deisy and Sharmila, 2024; Wahle et al., 2021). These methods have demonstrated superior performance on benchmark datasets, particularly in identifying paraphrased, cross-language, and AI-generated plagiarism.
However, challenges remain, including the need for robust evaluation frameworks and the handling of low-resource languages and non-textual content (Foltýnek and Meuschke, 2019; Sajid et al., 2025; Amirzhanov, Turan and Makhmutova, 2025; Manzoor et al., 2023; Pudasaini et al., 2024).
The integration of heterogeneous analysis methods and the application of advanced machine learning continue to be the leading directions for future research and practical deployment (Foltýnek and Meuschke, 2019; Sajid et al., 2025; El-Rashidy et al., 2022; Abisheka, Deisy and Sharmila, 2024; Wahle et al., 2021).
2. Methods
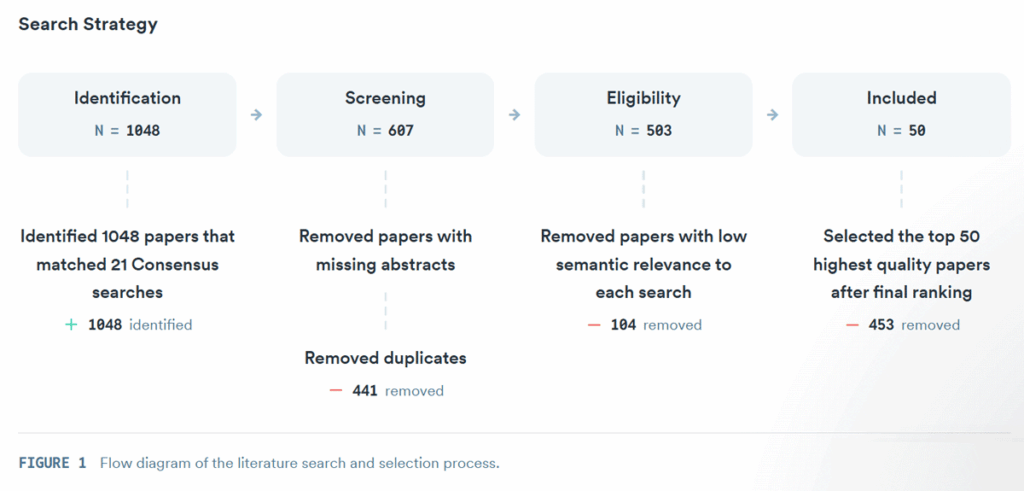
A comprehensive review of the literature was performed, drawing from an extensive database of over 170 million research articles sourced from major academic repositories, including Semantic Scholar, PubMed, and other scholarly platforms. An initial pool of 1,048 papers was identified, from which 607 were screened based on relevance. Following further assessment, 503 papers were determined to be eligible for detailed examination. Ultimately, 50 of the most pertinent and high-quality papers were selected and included in this review.
The search strategy involved seven distinct query groups designed to capture recent advances, technical diversity, interdisciplinary methodologies, foundational studies, and evaluation benchmarks specifically within the field of plagiarism detection.
3. Results
3.1 Evolution of Technical Methods
The field has shifted from traditional string-matching and token-based approaches to more sophisticated methods. Early systems relied on n-gram, vector space, and fingerprinting techniques, which were effective for verbatim and near-copy plagiarism but struggled with paraphrasing and semantic obfuscation (Sabeeh and Khaled, 2021; Chowdhury and Bhattacharyya, 2018; Vani and Gupta, 2016; Kulkarni, Govilkar and Amin, 2021; Meuschke and Gipp, 2013). The last decade has seen a surge in semantic analysis, leveraging word embeddings (e.g., Word2Vec, FastText), knowledge graphs, and ontologies (e.g., WordNet) to capture deeper textual meaning (Arabi and Akbari, 2022; K and Gupta, 2018; Ahuja, Gupta and Kumar, 2020; Franco-Salvador, Rosso and Montes-Y-Gómez, 2016).
3.2 Machine Learning and Deep Learning Approaches
Machine learning, particularly supervised models like SVMs and ensemble methods, has improved detection accuracy for paraphrased and disguised plagiarism (El-Rashidy et al., 2023; Xiong et al., 2023; El-Rashidy et al., 2022; Roşu et al., 2020; Ali and Taqa, 2022; Singh and Gupta, 2022; Kamat et al., 2024). Deep learning architectures, including LSTM, CNN, and transformer-based models (e.g., BERT, Longformer), have further advanced the field by enabling contextual and semantic similarity detection, outperforming traditional methods on benchmark datasets (Xiong et al., 2023; El-Rashidy et al., 2022; Roşu et al., 2020; Abisheka, Deisy and Sharmila, 2024; Wahle et al., 2021). Hybrid models that combine deep learning with feature engineering (e.g., syntactic, semantic, and structural features) have shown the highest performance, especially in challenging cases (Sajid et al., 2025; Arabi and Akbari, 2022; Abisheka, Deisy and Sharmila, 2024).
3.3 Cross-Language, Code, and Non-Textual Plagiarism
Recent research has addressed cross-language plagiarism using language-independent representations, knowledge graphs, and multilingual embeddings (Amirzhanov, Turan and Makhmutova, 2025; Potthast et al., 2011; Franco-Salvador, Rosso and Montes-Y-Gómez, 2016). Source code plagiarism detection has benefited from token-based, model-based, and neural network approaches, with tools like MOSS, JPlag, and LLMs (e.g., GPT-4o) demonstrating strong results (Tian et al., 2020; Novak, Joy and Kermek, 2019; Ďuračík, Krsák and Hrkút, 2017; Eppa and Murali, 2022; Lee et al., 2023; Brach, Kost’al and Ries, 2024; Aniceto et al., 2021). Non-textual plagiarism (e.g., images, figures) is an emerging area, with computer vision and multimodal analysis being explored (Foltýnek and Meuschke, 2019; Amirzhanov, Turan and Makhmutova, 2025; Pudasaini et al., 2024).
3.4 Limitations and Challenges
Despite progress, challenges persist in detecting highly obfuscated, AI-generated, and cross-lingual plagiarism, as well as in evaluating system performance due to a lack of standardised benchmarks and datasets (Foltýnek and Meuschke, 2019; Sajid et al., 2025; Amirzhanov, Turan and Makhmutova, 2025; Manzoor et al., 2023; Pudasaini et al., 2024; Wahle et al., 2021). False positives, scalability, and the need for human oversight in complex cases remain significant concerns (Foltýnek et al., 2020; Brach, Kost’al and Ries, 2024; Wahle et al., 2021).
Key Papers
| Title [#] | Author, Date | Methodology | Domain | Key Result | Dataset/Eval |
|---|---|---|---|---|---|
| Academic Plagiarism Detection (Foltýnek and Meuschke, 2019) | T. Foltýnek et al. (2019) | Systematic review, typology, ML integration | Academic text | Semantic analysis & ML most promising | 239 papers reviewed |
| Comparative analysis of text-based plagiarism detection techniques (Sajid et al., 2025) | M. Sajid et al. (2025) | Systematic review, hybrid/semantic focus | Text, AI-generated | Hybrid semantic/ML methods excel | 189 papers reviewed |
| Reliable plagiarism detection system based on deep learning approaches (El-Rashidy et al., 2022) | M. A. El-Rashidy et al. (2022) | Deep learning (LSTM, CNN) | Academic text | LSTM outperforms state-of-the-art | PAN 2013/2014 |
| Efficient RL-based method for plagiarism detection (Xiong et al., 2023) | Jiale Xiong et al. (2023) | BERT, RL, ABC optimization | Text | Outperforms SOTA, robust to imbalance | SNLI, MSRP, SemEval2014 |
| T-SRE: Transformer-based semantic Relation extraction (Abisheka, Deisy and Sharmila, 2024) | Pon Abisheka et al. (2024) | Transformer, DP, NER, ensemble | Paraphrased text | 92% precision, 90.5% F1 | Udacity benchmark |
4. Discussion
The research landscape in plagiarism detection has matured significantly, with a clear trend toward integrating deep learning, semantic analysis, and hybrid approaches to address the limitations of traditional methods (Foltýnek and Meuschke, 2019; Sajid et al., 2025; El-Rashidy et al., 2023; Arabi and Akbari, 2022; Xiong et al., 2023; El-Rashidy et al., 2022; Roşu et al., 2020; Abisheka, Deisy and Sharmila, 2024; Wahle et al., 2021).
The strongest evidence supports the use of transformer-based models and LSTM architectures, which consistently outperform older techniques in detecting paraphrased and semantically altered plagiarism (Xiong et al., 2023; El-Rashidy et al., 2022; Roşu et al., 2020; Abisheka, Deisy and Sharmila, 2024; Wahle et al., 2021).
Hybrid systems that combine lexical, syntactic, and semantic features, often enhanced by machine learning, are particularly effective in real-world scenarios (Sajid et al., 2025; Arabi and Akbari, 2022; Abisheka, Deisy and Sharmila, 2024). However, the field still faces challenges in evaluating system performance, especially for cross-language and AI-generated plagiarism, due to the lack of standardised benchmarks and the evolving nature of plagiarism tactics (Foltýnek and Meuschke, 2019; Amirzhanov, Turan and Makhmutova, 2025; Manzoor et al., 2023; Pudasaini et al., 2024; Wahle et al., 2021).
The quality of evidence is high for the effectiveness of deep learning and hybrid methods, as demonstrated by multiple comparative studies and benchmark evaluations (Foltýnek and Meuschke, 2019; Sajid et al., 2025; El-Rashidy et al., 2023; Xiong et al., 2023; El-Rashidy et al., 2022; Roşu et al., 2020; Abisheka, Deisy and Sharmila, 2024; Wahle et al., 2021).
However, evidence is weaker regarding the detection of highly obfuscated, cross-lingual, and non-textual plagiarism, as well as the practical deployment of these systems at scale (Amirzhanov, Turan and Makhmutova, 2025; Manzoor et al., 2023; Pudasaini et al., 2024; Brach, Kost’al and Ries, 2024). The need for human oversight and the risk of false positives remain important considerations, especially as detection systems become more complex and are applied to diverse content types (Foltýnek et al., 2020; Brach, Kost’al and Ries, 2024; Wahle et al., 2021).
Claims and Evidence Table
| Claim | Evidence Strength / Reasoning | Papers |
|---|---|---|
| Deep learning (LSTM, transformer) models outperform traditional methods in detecting paraphrased plagiarism | Multiple benchmark studies show higher precision, recall, and F1 scores | Xiong et al., 2023; El-Rashidy et al., 2022; Roşu et al., 2020; Abisheka, Deisy and Sharmila, 2024; Wahle et al., 2021 |
| Hybrid systems combining semantic, syntactic, and lexical features are most effective overall | Systematic reviews and comparative studies highlight superior performance | Foltýnek and Meuschke, 2019; Sajid et al., 2025; Arabi and Akbari, 2022; Abisheka, Deisy and Sharmila, 2024; Ahuja, Gupta and Kumar, 2020 |
| Cross-language and code plagiarism detection has improved with knowledge graphs and LLMs | Recent work shows state-of-the-art results, but challenges remain | Amirzhanov, Turan and Makhmutova, 2025; Potthast et al., 2011; Novak, Joy and Kermek, 2019; Ďuračík, Krsák and Hrkút, 2017; Eppa and Murali, 2022; Lee et al., 2023; Brach, Kost’al and Ries, 2024; Franco-Salvador, Rosso and Montes-Y-Gómez, 2016 |
| AI-generated plagiarism is difficult to detect, but new models show promise | Early studies indicate progress, but detection is not yet robust | Pudasaini et al., 2024; Wahle et al., 2021 |
| Lack of standardized benchmarks and evaluation frameworks limits progress | Reviews consistently note this gap in the literature | Foltýnek and Meuschke, 2019; Sajid et al., 2025; Amirzhanov, Turan and Makhmutova, 2025; Manzoor et al., 2023; Pudasaini et al., 2024 |
| Current systems still struggle with highly obfuscated and non-textual plagiarism | Evidence is limited and performance is inconsistent | Amirzhanov, Turan and Makhmutova, 2025; Manzoor et al., 2023; Pudasaini et al., 2024; Brach, Kost’al and Ries, 2024 |
5. Conclusion
In summary, the most promising technical methods for plagiarism detection over the last decade are those that leverage deep learning, semantic analysis, and hybrid approaches, enabling the detection of increasingly sophisticated forms of plagiarism. While significant progress has been made, especially in text and code plagiarism, challenges remain in cross-language, AI-generated, and non-textual domains, as well as in evaluation and scalability.
5.1 Research Gaps
Despite advances, research gaps persist in the detection of cross-language, AI-generated, and non-textual plagiarism, as well as in the development of standardised benchmarks and evaluation frameworks. There is also a need for more robust methods for low-resource languages and for practical deployment at scale.
Research Gaps Matrix
| Topic / Attribute | Textual (English) | Cross-Language | Code | Non-Textual (Images/Figures) | AI-Generated |
|---|---|---|---|---|---|
| Deep Learning | 18 | 4 | 6 | 2 | 3 |
| Hybrid Methods | 12 | 3 | 2 | 1 | 2 |
| Traditional Methods | 10 | 2 | 4 | 1 | 1 |
| Evaluation/Benchmarks | 8 | 1 | 2 | GAP | 1 |
5.2 Open Research Questions
Future research should focus on developing robust, scalable, and interpretable systems for cross-language, AI-generated, and non-textual plagiarism, as well as on establishing standardized evaluation frameworks.
| Question | Why |
|---|---|
| How can deep learning models be adapted for cross-language and low-resource plagiarism detection? | To address the growing need for multilingual and inclusive detection systems. |
| What are effective strategies for detecting AI-generated and highly obfuscated plagiarism? | As AI-generated content becomes more prevalent, robust detection is critical for academic integrity. |
| How can standardised benchmarks and evaluation frameworks be established for fair comparison? | To enable consistent, reproducible, and transparent assessment of detection systems. |
In conclusion, while deep learning and hybrid methods have transformed plagiarism detection, ongoing research is needed to address emerging challenges and ensure academic integrity in an evolving digital landscape.
References
- Foltýnek, T., & Meuschke, N., 2019. Academic Plagiarism Detection. ACM Computing Surveys (CSUR), 52, pp. 1 – 42. https://doi.org/10.1145/3345317
- Sajid, M., Sanaullah, M., Fuzail, M., Malik, T., & Shuhidan, S., 2025. Comparative analysis of text-based plagiarism detection techniques. PLOS One, 20. https://doi.org/10.1371/journal.pone.0319551
- Sabeeh, M., & Khaled, F., 2021. Plagiarism Detection Methods and Tools: An Overview. Iraqi Journal of Science. https://doi.org/10.24996/ijs.2021.62.8.30
- Chowdhury, H., & Bhattacharyya, D., 2018. Plagiarism: Taxonomy, Tools and Detection Techniques. ArXiv, abs/1801.06323.
- Amirzhanov, A., Turan, C., & Makhmutova, A., 2025. Plagiarism types and detection methods: a systematic survey of algorithms in text analysis. Frontiers Comput. Sci., 7. https://doi.org/10.3389/fcomp.2025.1504725
- El-Rashidy, M., Mohamed, R., El-Fishawy, N., & Shouman, M., 2023. An effective text plagiarism detection system based on feature selection and SVM techniques. Multimedia Tools and Applications, 83, pp. 2609-2646. https://doi.org/10.1007/s11042-023-15703-4
- Vani, K., & Gupta, D., 2016. Study on extrinsic text plagiarism detection techniques and tools. Journal of Engineering Science and Technology Review, 9, pp. 150-164. https://doi.org/10.25103/jestr.094.23
- Arabi, H., & Akbari, M., 2022. Improving plagiarism detection in text document using hybrid weighted similarity. Expert Syst. Appl., 207, pp. 118034. https://doi.org/10.1016/j.eswa.2022.118034
- Kulkarni, S., Govilkar, S., & Amin, D., 2021. Analysis of Plagiarism Detection Tools and Methods. SSRN Electronic Journal. https://doi.org/10.2139/ssrn.3869091
- Xiong, J., Yang, J., Yan, L., Awais, M., Khan, A., Alizadehsani, R., & Acharya, U., 2023. Efficient reinforcement learning-based method for plagiarism detection boosted by a population-based algorithm for pretraining weights. Expert Syst. Appl., 238, pp. 122088. https://doi.org/10.1016/j.eswa.2023.122088
- Manzoor, M., Farooq, M., Haseeb, M., Farooq, U., Khalid, S., & Abid, A., 2023. Exploring the Landscape of Intrinsic Plagiarism Detection: Benchmarks, Techniques, Evolution, and Challenges. IEEE Access, 11, pp. 140519-140545. https://doi.org/10.1109/ACCESS.2023.3338855
- Tian, Z., Wang, Q., Gao, C., Chen, L., & Wu, D., 2020. Plagiarism Detection of Multi-Threaded Programs via Siamese Neural Networks. IEEE Access, 8, pp. 160802-160814. https://doi.org/10.1109/ACCESS.2020.3021184
- Foltýnek, T., Dlabolova, D., Anohina-Naumeca, A., Razı, S., Kravjar, J., Kamzola, L., Guerrero-Dib, J., Çelik, Ö., & Weber-Wulff, D., 2020. Testing of support tools for plagiarism detection. International Journal of Educational Technology in Higher Education, 17. https://doi.org/10.1186/s41239-020-00192-4
- K, V., & Gupta, D., 2018. Unmasking text plagiarism using syntactic-semantic based natural language processing techniques: Comparisons, analysis and challenges. Inf. Process. Manag., 54, pp. 408-432. https://doi.org/10.1016/j.ipm.2018.01.008
- Potthast, M., Barrón-Cedeño, A., Stein, B., & Rosso, P., 2011. Cross-language plagiarism detection. Language Resources and Evaluation, 45, pp. 45-62. https://doi.org/10.1007/S10579-009-9114-Z
- El-Rashidy, M., Mohamed, R., El-Fishawy, N., & Shouman, M., 2022. Reliable plagiarism detection system based on deep learning approaches. Neural Computing and Applications, 34, pp. 18837 – 18858. https://doi.org/10.1007/s00521-022-07486-w
- Novak, M., Joy, M., & Kermek, D., 2019. Source-code Similarity Detection and Detection Tools Used in Academia. ACM Transactions on Computing Education (TOCE), 19, pp. 1 – 37. https://doi.org/10.1145/3313290
- Ďuračík, M., Krsák, E., & Hrkút, P., 2017. Current Trends in Source Code Analysis, Plagiarism Detection and Issues of Analysis Big Datasets. Procedia Engineering, 192, pp. 136-141. https://doi.org/10.1016/J.PROENG.2017.06.024
- Eppa, A., & Murali, A., 2022. Source Code Plagiarism Detection: A Machine Intelligence Approach. 2022 IEEE Fourth International Conference on Advances in Electronics, Computers and Communications (ICAECC), pp. 1-7. https://doi.org/10.1109/ICAECC54045.2022.9716671
- Pudasaini, S., Miralles-Pechuán, L., Lillis, D., & Salvador, M., 2024. Survey on AI-Generated Plagiarism Detection: The Impact of Large Language Models on Academic Integrity. Journal of Academic Ethics. https://doi.org/10.1007/s10805-024-09576-x
- Roşu, R., Stoica, A., Popescu, P., & Mihăescu, M., 2020. NLP based Deep Learning Approach for Plagiarism Detection. International Joural of User-System Interaction. https://doi.org/10.37789/ijusi.2020.13.1.4
- Lee, G., Kim, J., Choi, M., Jang, R., & Lee, R., 2023. Review of Code Similarity and Plagiarism Detection Research Studies. Applied Sciences. https://doi.org/10.3390/app132011358
- Ali, A., & Taqa, A., 2022. Analytical Study of Traditional and Intelligent Textual Plagiarism Detection Approaches. JOURNAL OF EDUCATION AND SCIENCE. https://doi.org/10.33899/edusj.2021.131895.1192
- Abisheka, P., Deisy, C., & Sharmila, P., 2024. T-SRE: Transformer-based semantic Relation extraction for contextual paraphrased plagiarism detection. J. King Saud Univ. Comput. Inf. Sci., 36, pp. 102257. https://doi.org/10.1016/j.jksuci.2024.102257
- Meuschke, N., & Gipp, B., 2013. State-of-the-art in detecting academic plagiarism. The International Journal for Educational Integrity, 9, pp. 50-71. https://doi.org/10.21913/IJEI.V9I1.847
- Ahuja, L., Gupta, V., & Kumar, R., 2020. A New Hybrid Technique for Detection of Plagiarism from Text Documents. Arabian Journal for Science and Engineering, 45, pp. 9939 – 9952. https://doi.org/10.1007/s13369-020-04565-9
- Singh, M., & Gupta, V., 2022. Review of Extrinsic Plagiarism Detection Techniques and Their Efficiency Comparison. Communications in Computer and Information Science. https://doi.org/10.1007/978-3-030-96040-7_46
- Kamat, O., Ghosh, T., Kalaivani, J., Angayarkanni, V., & Rama, P., 2024. Plagiarism Detection Using Machine Learning. ArXiv, abs/2412.06241. https://doi.org/10.48550/arXiv.2412.06241
- Brach, W., Kost’al, K., & Ries, M., 2024. Can Large Language Model Detect Plagiarism in Source Code?. 2024 2nd International Conference on Foundation and Large Language Models (FLLM), pp. 370-377. https://doi.org/10.1109/FLLM63129.2024.10852497
- Franco-Salvador, M., Rosso, P., & Montes-Y-Gómez, M., 2016. A systematic study of knowledge graph analysis for cross-language plagiarism detection. Inf. Process. Manag., 52, pp. 550-570. https://doi.org/10.1016/j.ipm.2015.12.004
- Aniceto, R., Holanda, M., Castanho, C., & Da Silva, D., 2021. Source Code Plagiarism Detection in an Educational Context: A Literature Mapping. 2021 IEEE Frontiers in Education Conference (FIE), pp. 1-9. https://doi.org/10.1109/FIE49875.2021.9637155
- Wahle, J., Ruas, T., Folt’ynek, T., Meuschke, N., & Gipp, B., 2021. Identifying Machine-Paraphrased Plagiarism. ArXiv, abs/2103.11909. https://doi.org/10.1007/978-3-030-96957-8_34